
Serializing an Async-with-Callback Endpoint Across an OIC Landscape
Every integration platform eventually runs into an external system that just can’t keep up. Most of the time it’s a throughput issue — too many requests per second, easy to throttle. Occasionally, though, you hit something far more constraining: an endpoint that can only handle one in-flight request at a time, across all of your callers, full stop. Call it twice in parallel and the second call doesn’t queue, doesn’t wait, doesn’t degrade gracefully. It fails outright.
This post walks through how to safely coordinate calls to one of these endpoints from an Oracle Integration Cloud (OIC) landscape, where many integrations from many projects all need to hit the same external service. We’ll work through the use case in detail, lay out the constraints we’re operating under, then build up the design that satisfies them.
The Use Case
We have an external endpoint — a partner API, a legacy system, an SaaS service, the specific provenance doesn’t matter — with the following behaviour:
- It is asynchronous with callback. You POST a request to it. It accepts the work and responds quickly with a 202 acknowledgement. Some time later (seconds, minutes, occasionally longer) it fires a callback at an HTTPS endpoint you’ve registered with it, carrying the actual result.
- It can only process one request at a time. Whatever internal resource it’s gating — a database lock, a session token, a single-threaded worker — it cannot handle two requests in flight simultaneously.
- Concurrent calls fail loudly. If a second request arrives while the first is still being processed (i.e., before its callback has fired), the endpoint responds with 502 Bad Gateway to the second caller. It does not queue. It does not retry. It just rejects.
On the OIC side, we have many integrations that need to call this endpoint. They live in different projects, are owned by different teams, and run on their own schedules. They don’t coordinate with each other today, and we can’t realistically expect them to. The serialization has to be enforced centrally — somewhere in the path between caller and endpoint — and it has to be airtight.
The subtle bit is the implication of “async with callback” on what busy means. Most concurrency patterns assume that “the HTTP call has returned” equals “the resource is free again.” Here, that’s wrong. The endpoint stays busy from the moment we POST until the moment we receive its callback. That window can be many seconds long. Whatever gating mechanism we build has to keep the endpoint marked busy for the entire call-to-callback round trip — not just the synchronous portion.
The Constraints
A few specific restrictions shape the design:
Serialization must cover every OIC caller. Not every integration, individually rate-limited. Not every project, separately throttled. One global lane, with everyone funnelled through it. Any caller that bypasses the gate breaks the invariant.
Scheduled integrations are not available. OIC has a useful guarantee — a scheduled integration is limited to one concurrent scheduled run — which would otherwise be the obvious serialization primitive. For governance, observability, or licensing reasons, it’s off the table in this landscape. The serialization has to come from somewhere else.
The request queue must be in OCI, not a database table. Request volume is high enough that a DB-backed queue would add unacceptable latency on every enqueue and dequeue. We need a managed, low-latency, FIFO-capable messaging service. OCI offers exactly this in OCI Streaming.
A small DB table is fine for low-frequency coordination state. Specifically, we’ll use a single row in a small dedicated table to track whether the endpoint is currently busy. This is two indexed UPDATEs per call cycle — nowhere near the latency profile that ruled out a DB-backed request queue. Different access pattern, different tradeoff.
With these four constraints in mind, the design falls into three layers: a request queue (OCI Streaming), a gating mechanism (a DB permit row), and two thin integrations that connect them.
Why the Obvious Solutions Don’t Work
Before getting to the design, a quick word on why several intuitive approaches fall over. They’re worth ruling out explicitly, because each is the first thing someone reaches for.
“Just have all callers go through a single shared wrapper integration.” Tempting, but it doesn’t help. App-driven integrations in OIC spawn a fresh runtime instance per invocation. If five integrations call your wrapper at the same moment, you get five parallel instances of the wrapper, all racing toward the endpoint. Sharing a definition doesn’t share execution.
“Retry on 502 with exponential backoff.” This turns a concurrency problem into a thundering-herd problem. Every caller backs off and then retries, all at roughly the same time, multiplying load on the very endpoint that couldn’t handle the load to begin with.
“Use a stage file or a lookup as a global flag.” OIC has no shared transactional state across integration instances. Any check-and-set you build on top of these will have a race condition between “check the flag” and “set the flag” — two callers can both see “free” before either flips it to “busy.”
“Lock during the HTTP call.” Even if you could lock during a synchronous call, the async-with-callback shape means the lock would release at exactly the wrong moment — when the 202 arrives, while the endpoint is still working. You’d be back to 502s.
The honest answer is that we need (a) a shared, low-latency queueing layer that all producers can publish to, (b) a coordination primitive that survives outside any single integration instance, and (c) a way to mark the endpoint “busy” for the entire call-to-callback window — not just the synchronous portion.
The Design
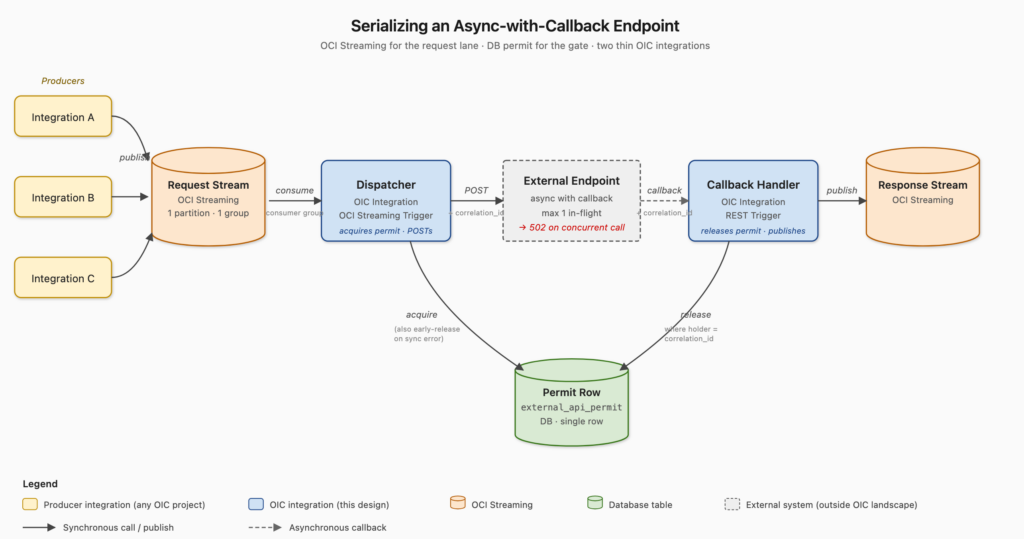
Five components. Each does exactly one thing.
1. The request stream (OCI Streaming)
A single stream with exactly one partition. Every OIC integration that needs to call the external endpoint publishes a request message here, using the OCI Streaming Adapter as an invoke. The message carries:
- A
correlation_id(UUID, generated by the producer) — this will travel through the rest of the system and back via the callback. - The payload to forward to the external endpoint.
- A
reply_tohint (callback URL, response stream subscription key, or “none” for fire-and-forget). - Optional
callerandcreated_atmetadata for traceability.
Publishing to OCI Streaming is fast — single-digit milliseconds in-region — so the enqueue cost from a producer’s perspective is negligible.
The single-partition design isn’t an accident. OCI Streaming guarantees ordering within a partition, not across partitions. By using one partition, we guarantee strict FIFO across every caller in the landscape. It also unlocks the next trick.
2. The dispatcher (OCI Streaming trigger)
One app-driven integration with the OCI Streaming Adapter configured as a trigger:
- Stream: the request stream above.
- Partition: the single partition (set explicitly — don’t use “Default”).
- Consumer group: a dedicated name, e.g.
PARTNER_API_SERIALIZER. - Polling frequency: low single digits of seconds.
- Max records: small (1–5).
Now we exploit a property of the consumer-group protocol. When multiple consumer instances join the same group, OCI Streaming assigns each partition to exactly one consumer in that group at a time. Even if OIC’s runtime spawns multiple dispatcher instances internally, the broker hands the single partition to one of them. The others sit idle.
That gives us our first guarantee: at most one dispatcher instance is reading from the request stream at any moment, landscape-wide. It comes from OCI Streaming itself, enforced by the broker — not by anything in our code.
But this only solves half the problem. The dispatcher might be a singleton, but its calls to the endpoint are still asynchronous. Acquiring the permit (the next component) is what extends the lock through the full callback window.
3. The permit row (DB)
A single row in a tiny dedicated table:
CREATE TABLE external_api_permit (
name VARCHAR2(64) PRIMARY KEY,
state VARCHAR2(16) NOT NULL, -- 'FREE' | 'TAKEN'
holder VARCHAR2(128), -- correlation_id of current holder
acquired_at TIMESTAMP,
released_at TIMESTAMP
);
INSERT INTO external_api_permit (name, state)
VALUES ('PARTNER_API', 'FREE');
One row. One permit. That row’s state is the entire coordination state for the whole pattern. If state = 'FREE', the endpoint is idle and the next dispatcher can call it. If state = 'TAKEN', the endpoint is busy with the request identified by holder, and no one else may call.
Two SQL statements operate on it:
Acquire:
UPDATE external_api_permit
SET state = 'TAKEN',
holder = :correlation_id,
acquired_at = SYSTIMESTAMP,
released_at = NULL
WHERE name = 'PARTNER_API'
AND ( state = 'FREE'
OR acquired_at < SYSTIMESTAMP
- NUMTODSINTERVAL(:max_callback_seconds, 'SECOND') );
That single statement does two jobs. It acquires the permit if it’s FREE, or it steals the permit if the previous holder has been sitting on it longer than the maximum allowed callback window. Rows-affected = 1 means you have the permit; rows-affected = 0 means someone else legitimately holds it.
Release:
UPDATE external_api_permit
SET state = 'FREE',
holder = NULL,
released_at = SYSTIMESTAMP
WHERE name = 'PARTNER_API'
AND holder = :correlation_id;
The holder = :correlation_id guard is critical. It means only the request that currently holds the permit can release it. Anything else — duplicate callbacks, late callbacks for permits that have already been stolen, callbacks for some other request entirely — affects 0 rows and is silently a no-op. The release is naturally idempotent.
4. The dispatcher’s logic (putting them together)
For each request message it receives from the stream, the dispatcher does:
rows = UPDATE external_api_permit ... (acquire as above) ...
if rows == 0:
do not commit offset
exit # try again on next poll
response = call_external(payload, correlation_id)
if response.status not in (200, 202):
release_permit(correlation_id) # no callback will arrive
commit_offset()
exit
A successful run acquires the permit, fires the call, and exits — leaving the permit row in TAKEN state. The dispatcher does not wait for the callback. It doesn’t need to. The permit stays held until something else flips it back to FREE.
If the permit couldn’t be acquired, the dispatcher simply doesn’t commit the stream offset. The same message will be re-fetched on the next poll, and the dispatcher will try again. This is natural back-pressure: requests accumulate in the stream while the endpoint is busy, and drain out in order as soon as it’s free.
5. The callback handler
A separate app-driven integration with a REST trigger. The external endpoint POSTs to this when its async work is done.
On receipt:
- Read the
correlation_idfrom the callback payload. - Publish the response to a response stream (a second OCI Streaming stream, multiple partitions are fine here — no serialization needed on the return path). Producers — or whatever downstream consumer is interested — pick up the response from there, filtering by
correlation_id. - Run the release UPDATE.
- Return 200 to the external endpoint.
The moment step 3 completes, the permit row is FREE again, and the next dispatcher poll will acquire it and dispatch the next pending request. The serialization window closes exactly when the callback says it should.
How the Design Handles Failure
Permit-based gating is elegant, but it has sharp edges. These are the four failure modes worth designing for explicitly.
The dispatcher crashes between acquire and call
The permit row is TAKEN, but the HTTP call was never made. No callback will ever arrive. Without recovery, this would stall the system forever.
The recovery is the same one that handles the next failure mode, so see below.
Mitigation otherwise: keep the dispatcher’s code path between the acquire UPDATE and the HTTP call as short and dumb as possible. No business logic, no enrichment, no surprise failure points. Acquire → call → commit.
The callback never arrives
The endpoint dies, the network partitions, the partner system has a bad afternoon. The permit is TAKEN, no callback is coming.
Look again at the acquire UPDATE’s WHERE clause:
WHERE name = 'PARTNER_API'
AND ( state = 'FREE'
OR acquired_at < SYSTIMESTAMP
- NUMTODSINTERVAL(:max_callback_seconds, 'SECOND') );
If the previous holder has been sitting on the permit longer than max_callback_seconds — which you set to comfortably more than the worst legitimate callback time — the next dispatcher to run steals the permit and dispatches its own request. The system recovers automatically, on its own, with no external watchdog and no scheduled integration. The stuck request even gets retried, because its stream offset was never committed.
Choosing max_callback_seconds is a real tuning decision. Too short and you’ll steal permits from legitimately in-flight calls, causing the dreaded 502 you’re trying to avoid. Too long and stuck requests sit around. A reasonable starting point is 2× the 99th-percentile callback latency, refined from production telemetry. If your callbacks normally arrive within 30 seconds, start with 60–90 seconds. If they can take 10 minutes, you need a much wider window.
A late callback for a permit that was stolen does not break anything: its release UPDATE matches holder = :stale_correlation_id, which is no longer the current holder, so 0 rows are updated. Importantly, the response itself is still published to the response stream — silently dropping late responses is worse than processing them.
Duplicate callbacks
The endpoint retries because our handler timed out, and now we get the same callback twice.
Already handled. The release UPDATE’s holder = :correlation_id guard means the second callback updates 0 rows: the permit has already been released and possibly reacquired by a later request. The duplicate callback’s response is still published to the response stream (we shouldn’t lose data), but the permit is not double-released.
A synchronous error response from the endpoint
A malformed payload, an expired credential, a “you can’t do that” — anything that the endpoint rejects without queuing the work. We’ve acquired the permit, but no callback will fire.
The early-release branch in the dispatcher snippet covers this: any non-success synchronous response triggers an immediate release. The permit returns to FREE and the next request can proceed without waiting for max_callback_seconds to elapse.
What Callers See
From a producer’s perspective, the entire design is invisible. They publish a message to the request stream and walk away. They get their response — eventually — via whichever return channel was wired up: a callback URL they exposed, a subscription to the response stream, or a thin synchronous wrapper that hides the asynchrony altogether.
The hard problem — how do we make sure two callers don’t hit this endpoint at the same time? — is contained entirely in the dispatcher, the permit row, and the callback handler. The rest of the landscape gets to pretend the endpoint behaves reasonably.
That’s the test of a good integration boundary: the pain lives in one place, surfaced as a clean abstraction.
Takeaways
- The serialization problem isn’t really about HTTP concurrency — it’s about coordinating the call-to-callback window. Async-with-callback endpoints stay busy long after the synchronous call returns; your gating mechanism has to extend with them.
- OCI Streaming gives you single-consumer semantics for free via the consumer-group protocol. One stream, one partition, one consumer group, and the broker enforces that only one consumer is ever reading. That’s your ordered queue layer, sorted.
- A single DB row is a perfectly good permit. Two indexed UPDATEs per call cycle is nowhere near the load that makes a DB queue too slow. Use the right tool for each part of the problem — fast messaging for the request stream, durable state for the permit.
- The timestamp in the permit row is a built-in watchdog. Combine
state = 'FREE' OR acquired_at < (now - max_callback_seconds)in the acquire WHERE clause and lost callbacks recover themselves on the next dispatcher poll. No scheduler, no external process, no human in the loop. - The
holder = :correlation_idguard on release makes the whole protocol naturally idempotent. Duplicate callbacks, late callbacks, callbacks for already-stolen permits — all become harmless no-ops on the permit row, while their responses still flow through to listeners.
The pattern generalises beyond OIC, beyond OCI, beyond this specific endpoint shape. Anywhere you have a resource that can hold N concurrent units of work and need to ensure callers respect that limit: model the limit as N permits in a shared table, gate access on permit acquisition, release on completion, recover via timestamp. Concurrency theory has known this for sixty years. A one-row table just gives us a cheap, durable place to keep the permits.